





I. Introduction▲
La génération de courriers d'après un modèle est un sujet auquel je suis souvent confronté dans mes applications de gestion.
Jusqu'à présent on disposait de l'automation pour réaliser ce genre de tâche.
Cette interface com a évoluée au fil des ans et des versions successives d'office, mais il n'est pas toujours très facile de trouver de la documentation sur le sujet, et surtout :
-On est obligé de disposer de Word sur le poste de traitement.
-Le manque de rapidité de l'interface peut être un frein à la génération d'un volume important de document.
Avec office 2007, Microsoft met en avant une nouvelle structure de document l'openXML.
Ce nouveau format de données n'utilise que des standards ouverts comme : ZIP, XML, XMLSchema, png,…
Je ne vais pas rentrer dans les détails sur le format OpenXML nombre d'articles sur Internet sont disponibles sur le sujet.
L'accès aux différents éléments constituants le fichier est très simple:
Celui-ci étant au format zip il est aisé de le renommer, et d'accéder aux différents éléments le constituant.
Du coup il devient relativement facile de manipuler le fichier XML document.xml contenant les données.
Vous utilisez encore office 2003?
Qu'à cela ne tienne, il existe un pack de compatibilité Microsoft Office pour les formats de fichier Word, Excel et PowerPoint 2007:
http://www.microsoft.com/downloads/details.aspx?displaylang=fr&FamilyID=941b3470-3ae9-4aee-8f43-c6bb74cd1466
II. Objectif mailing en C++ ou en C▲
J'ai annoncé la couleur dans le titre, mon objectif est de réaliser une interface en C++ et C permettant de générer des documents Word au format .docx, mon outil de développement sera Visual C++ 2008, néanmoins la solution sera aussi compilable en Visual 6.0 qui est encore beaucoup utilisé.
Pour cela je vais avoir besoin de deux bibliothèques :
Une pour gérer des fichiers au format ZIP, j'ai choisi ZipArchive.
Une autre pour gérer un fichier au format XML mon choix s'est porté sur TinyXML.
Détails du traitement :
Un fichier modèle servira de base pour générer les documents.
Les zones à remplacer dans mon cas seront délimitées mais le choix reste libre.
Exemple :
Pour un simple mailing je vais devoir remplir automatiquement l'adresse du destinataire que je vais écrire comme suit :
<NOM> <PRENOM>
<ADRESSE1>
<ADRESSE2>
<CDP> <VILLE>
Le traitement devra donc repérer ces zones dans le fichier XML et les remplacer par les données réelles.
Après avoir mis en place ces éléments je me suis intéressé aux tableaux, le but étant de pouvoir repérer un tableau grâce au texte d'une cellule et de fournir les traitements suivants:
- Connaitre la taille du tableau en ligne et colonne.
- Sélectionner une ligne et/ou une colonne pour récupérer ou mettre à jour le texte d'une cellule.
- Rajouter une ligne d'après une ligne existante.
Une génération de courrier suivra le cycle de traitement suivant :
1) Déclaration du fichier modèle.
2) Décompression du fichier dans un répertoire temporaire portant le nom du fichier.
3) Réalisation d'une copie de sauvegarde du fichier document.xml.
4) Analyse du fichier document.xml avec TinyXML.
5) Spécification des zones types à remplacer avec leurs valeurs respectives par l'utilisateur.
6) Sauvegarde du fichier XML par TinyXML.
7) Reconstruction d'un fichier .docx portant le nom spécifié par l'utilisateur.
8) Restitution du fichier document.xml d'origine d'après la copie.
9) Retour à la phase 4).
III. Programmation de l'interface▲
Contraintes :
- Je veux disposer d'une classe de traitement en C++ et d'un jeu de fonctions en C contenus dans une DLL autonome.
- Mon interface fonctionnera dans un environnement Unicode ou multi-bytes.
Pour faciliter ce traitement j'utiliserai la classe ATL/MFC CString qui permet de passer facilement entre les deux modes.
Comme je suis conscient que cette interface pourrait être utilisée sans les MFC (cas de la dll en C pour réduire la taille),
je proposerai un mode de compilation proposant les classes CString CStringA et CStringW de substitution dans un environnement non MFC ou les classes CStringA et CStringW avec Visual C++ 6.0.
Ce jeu de classes s'appuiera sur la classe string de TinyXML que j'ai remaniée et complétée en classe patron (Template) pour manipuler le mode Unicode ou multi-bytes.
-Le format OpenXML codifie les données selon la norme UTF-8 (UCS transformation format 8 bits), celle-ci permet de coder de l'Unicode sous une suite de 4 octets maximum.
Les caractères dont le code ASCII est supérieur à 127 sont codés sur plusieurs octets.
Il faudra donc disposer d'une fonction de décodage et d'encodage des données pour modifier le fichier XML.
Après quelques recherches sur Internet je n'ai pas trouvé de solution satisfaisante.
J'ai donc réalisé deux fonctions pour ces traitements d'après la description donnée dans Wikipédia
//-------------------------------------------------------------------------
CStringA UTF8EncodeString(const CStringA str)
{
CStringW input(str);
CStringA output;
#if _MSC_VER <= 1200
for(int i=0; i < input.GetLength(); i++)
#else
for(unsigned int i=0; i < input.GetLength(); i++)
#endif
{
// 0xxxxxxx
if(input[i] < 0x80)
{
output+=input[i];
}
// C0 80
// 110xxxxx 10xxxxxx
else if((input[i] > 0x7F) && (input[i] < 0x800))
{
output+=static_cast<unsigned char>(0xC0 | (input[i] >> 6));
output+=static_cast<unsigned char>(0x80 | (input[i] & 0x3F));
}
// E0 80 80
// 1110xxxx 10xxxxxx 10xxxxxx
else if(input[i] < 0x8000)
{
output+=static_cast<unsigned char>(0xE0 | (input[i] >> 12));
output+=static_cast<unsigned char>(0x80 | (input[i] >> 6 & 0x3F));
output+=static_cast<unsigned char>(0x80 | (input[i] & 0x3F));
}
else
{ // F0 80 80 80
//11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
output+=static_cast<unsigned char>(0xF0 | (input[i] >> 12)>>6);
output+=static_cast<unsigned char>(0x80 | (input[i] >> 12 & 0x3F));
output+=static_cast<unsigned char>(0x80 | (input[i] >> 6 & 0x1F));
output+=static_cast<unsigned char>(0x80 | (input[i] & 0x3F));
}
}
return output;
}
//-------------------------------------------------------------------------
CStringA UTF8DecodeString(const CStringA input)
{
CStringW output;
#if _MSC_VER <= 1200
for(int i=0; i < input.GetLength();i++)
#else
for(unsigned int i=0; i < input.GetLength();i++)
#endif
{
// F0 80 80 80
//11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
if((input[i] & 0xFE) == 0xFE)
{
output+= static_cast<wchar_t>(((input[i] & 7 )<< 18) | ((input[i+1] & 0x3F) << 12) | ((input[i+2] & 0x3F) << 6) | (input[i+3] & 0x3F));
i += 3;
}
else
// E0 80 80
// 1110xxxx 10xxxxxx 10xxxxxx
if((input[i] & 0xE0) == 0xE0)
{
output+= static_cast<wchar_t>(((input[i] & 0x0F) << 12) | ((input[i+1] & 0x3F) << 6) | (input[i+2] & 0x3F));
i += 2;
}
// C0 80
// 110xxxxx 10xxxxxx
else if((input[i] & 0xC0) == 0xC0)
{
output+= static_cast<wchar_t>(((input[i] & 0x1F) << 6) | (input[i+1] & 0x3F));
i ++;
}
// 0xxxxxxx
else if(input[i] < 0x80) output+=input[i];
}
return CStringA(output);
}
// tests:
CStringA input,output;
input="é";
output=UTF8EncodeString(input);
TRACE("\n output é:%s",static_cast<const char *>(output));
output=UTF8DecodeString(output);
TRACE("\n output é:%s",static_cast<const char *>(output));
input="€";
output=UTF8EncodeString(input);
TRACE("\n output €:%s",static_cast<const char *>(output));
output=UTF8DecodeString(output);
TRACE("\n output é:%s",static_cast<const char *>(output));Notes:
-Une chaine au format UTF8 peut être contenue dans une CString multi bytes.
-j'ai implémenté la codification sur 4 octets mais l'exemple de Wikipédia avec le "?" ne semble pas correct dans ce cas puisque son code ASCII est égal à 63.
-Ce code ne fonctionne pas directement avec Visual 6.0 à cause des CString: On ne dispose pas de CStringA et de CStringW...
TinyXML génère un fichier XML " propre " avec des blancs pour implémenter l'indentation des balises XML, Word 2007 génère un fichier sans blancs et retours chariots pour avoir un fichier compact.
J'ai donc modifié TinyXML pour disposer d'un mode permettant d'ignorer l'indentation et les retours chariots pour gagner en compacité.
Au problème rencontré, TinyXML tronque le dernier blanc d'une donnée avant le caractère d'ouverture de la balise de fin champ.
J'ai dû procéder à une correction pour éviter d'avoir des mots collés dans le document final, ce qui est gênant pour un document Word…
IV. Composants de la solution▲
Ma solution se composera de quatre composants, un par type de traitement :
-Une classe de décompression d'un fichier en répertoire portant le nom du fichier.
-Une classe de compression d'un répertoire en un fichier.
-Une classe d'analyse du fichier document.xml.
-Une classe de Traitement pour le mail fédérant les autres objets.
IV-a. Compression et décompression du document▲
Commençons par les classes de compression et décompression présentées dans le diagramme ci-dessous :
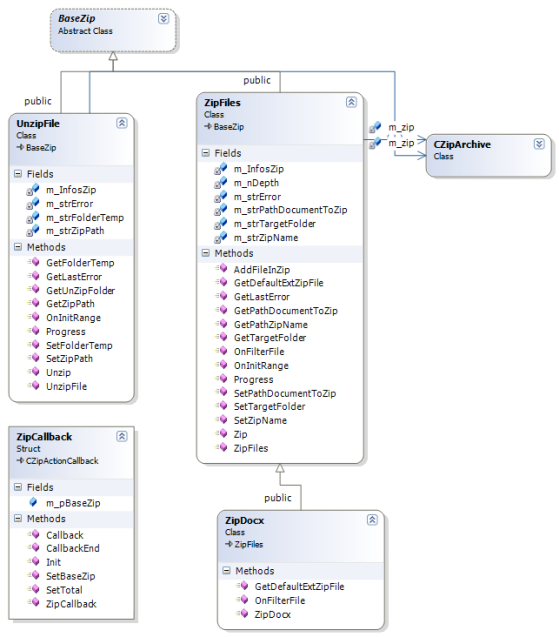
Les classes UnZipFile et ZipFiles héritent de la classe de base BaseZip.
Celle-ci contient quelques fonctions statiques et un mécanisme virtuel pour l'affichage des informations pendant la phase de compression ou de décompression.
Ces informations sont transmisses par l'intermédiaire de la classe ZipCallBack qui possède un pointeur sur la classe de base BaseZip.
La classe UnZipFile :
Son rôle :
Décompresser un fichier dans un répertoire portant le nom du fichier sans l'extension.
Si le répertoire racine de destination n'est pas spécifié le répertoire temporaire de Windows sera utilisé.
Descriptions des méthodes :
UnzipFile(const TCHAR *szdocument=NULL,const TCHAR *szFolderTemp=NULL)Constructeur par défaut, si szDocument est défini on procède à la décompression dans le répertoire Racine szFolterTemp, si elle est nulle dans le répertoire temporaire Windows.
void SetZipPath(const TCHAR *szPath):Réglage chemin d'origine du document zip
CString GetZipPath(){return m_strZipPath;}Récupération du chemin d'origine du zip
void SetFolderTemp(const TCHAR *szFolderTemp);Fixe le répertoire de travail pour la décompression, par défaut si szFolderTemp est null Windows\temp
CString GetFolderTemp(){return m_strFolderTemp;}Renvoie le chemin du répertoire de travail
CString GetUnZipFolder();Renvoie le chemin du dossier généré dans le répertoire de travail, c'est à dire le répertoire de travail + le nom du document.
CStringA GetLastError(){return m_strError;}Renvoie sous forme de chaine la dernière erreur récupérée de GetLastError()
Virtual void OnInitRange(DWORD nSizeFile,const TCHAR *szFileName){}
Fonction virtuelle appelée pour renseigner une interface graphique sur la tâche en cours.
Attention szFileName peut être nulle, pour initialiser un range d'un progressCtrl on écrira SetRange(0,nSizeFile)
virtual void Progress(int iProgress){}Appelée lors de la décompression pour indiquer l'avancement.
bool Unzip();Procède à la décompression peut être appelée par le constructeur. Utilisation :
try
{
UnzipFile Unzip(_T("Test.docx"));
}
catch(std::exception& e)
{
afxDump << _T("erreur") << e.what() ;
}
// Ou
UnzipFile Unzip;
Unzip.SetZipPath(_T("Test.docx"));
if(!Unzip.Unzip())
afxDump << _T("erreur") << Unzip.GetLastError() ;La classe ZipFile:
Son rôle :
Compresser en un fichier les éléments contenus dans un répertoire.
Le nom du fichier correspondant au nom du répertoire, l'extension du fichier par défaut étant .zip.
Descriptions des méthodes :
ZipFiles(const TCHAR *szPathdocumentToZip,const TCHAR *szTargetFolder=NULL)constructeur par défaut ,szPathdocumentToZip indique le chemin du répertoire à compresser, le fichier résultant est stocké à l'emplacement szTargetFolder où dans le répertoire courant si cette variable est nulle.
void SetPathDocumentToZip(const TCHAR *szPath)Fixe le chemin du répertoire à zipper, initialise par défaut le nom du zip au nom du répertoire.
CString GetPathDocumentToZip()Renvoie le chemin du répertoire à zipper.
void SetTargetFolder(const TCHAR *szTargetFolder)Fixe le répertoire de destination du document, si szTargetFolder est nulle : le répertoire courant.
CString GetTargetFolder()Renvoie le répertoire de destination du document
void SetZipName(const TCHAR *szZipName)Fixe le nom du document Zip final, si le chemin est fourni SetTargetFolder est appelée pour mémoriser le chemin.
CString GetPathZipName();Récupération du chemin du document généré : le répertoire de destination + le nom de l'archive fixée par SetZipName .
virtual bool OnFilterFile(const TCHAR *szCurrentFile)Permet de filtrer les fichiers à compresser, pour filtrer le fichier renvoyez false,renvoie true par défaut
CStringA GetLastError()Renvoie la dernière erreur détectée.
bool Zip();Compresse le répertoire désigné par SetPathDocumentToZip.
bool AddFileInZip(const TCHAR *szPath);Rajoute un fichier ou répertoire à l'archive en cours.
virtual void OnInitRange(DWORD nSizeFile,const TCHAR *szFileName)
Fonction virtuelle appelée pour renseigner une interface graphique sur la tache en cours.
Attention szFileName peut être nulle, pour initialiser une plage d'un progressCtrl on écrira SetRange(0,nSizeFile)
virtual void Progress(int iProgress){}Appelée lors de la décompression pour indiquer l'avancement.
virtual CString GetDefaultExtZipFile(){return _T(".zip");}
Fonction virtuelle retournant l'extension par défaut du fichier généré, retourne .zip par défaut.
Utilisation :
ZipDocx Zip;
Zip.SetPathDocumentToZip(Unzip.GetUnZipFolder());
Zip.SetTargetFolder(NULL);
Zip.SetZipName(_T("essai"));
if(!Zip.Zip())
#ifdef _DEBUG
afxDump << _T("erreur ") << Zip.GetLastError() ;
#else
{
str=_T("erreur")+Zip.GetLastError();
AfxMessageBox(str);
}
#endifIV-b. Analyse XML du document et mailing▲
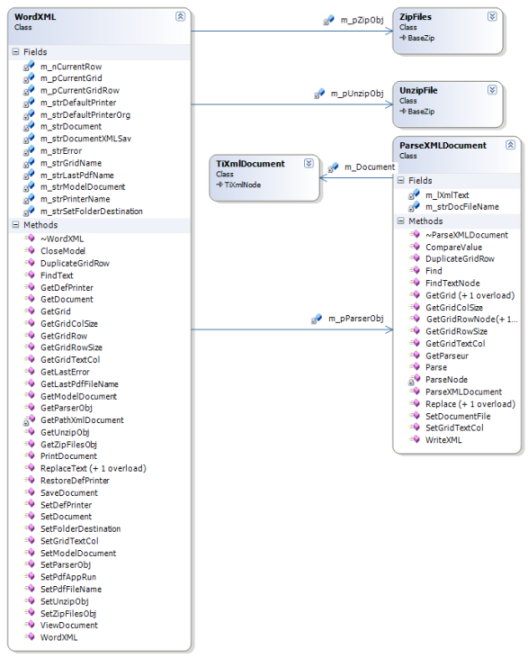
La classe ParseXMLDocument :
Son rôle :
Cette classe s'occupe d'analyser le fichier document.xml.
Chaque élément repéré comme étant du texte est stocké dans une liste :
std::list<TiXmlText*> m_lXmlText;
Celle-ci sera parcourue pour la recherche ou le remplacement de zones.
L'implémentation actuelle permet la recherche et le remplacement de zones existantes, ainsi que la modification de cellules ou l'ajout d'une ligne dans un tableau
Méthode de parcours du fichier document.xml:
En partant de la racine du document on énumère tous les éléments, pour chaque élément on va chercher tous les éléments enfants le constituant, le parcours est donc récursif.
void ParseNode(TiXmlNode* node)
{
if(node->ToElement())
{
TiXmlNode *elem =node;
for(elem=elem->FirstChild();elem;elem=elem->NextSiblingElement())
{
if(elem->ToElement())
{
TiXmlAttribute* attrib=elem->ToElement()->FirstAttribute();
for ( ; attrib; attrib = attrib->Next() )
{
#ifdef _DEBUG
TRACE("\n Name:%s: Value:%s",attrib->Name(),attrib->Value());
#endif
}
ParseNode(elem);
}
else
{
if(elem->ToText())
{
m_lXmlText.push_back(elem->ToText());
#ifdef _DEBUG
TRACE("\n (%s) Texte:%s",elem->Parent()->Value(),elem->Value());
#endif
}
}
}
}
}
for (TiXmlNode* node=m_Document.FirstChild(); node; node=node->NextSibling() )
{
ParseNode(node);
}
Comme le montre le code ci-dessus le parcours est très simple, quand on détecte un élément de texte on le stocke dans la liste.
Méthode de reconnaissance d'un tableau:
Un tableau est identifié par la balise xml w:tbl, chaque ligne du tableau par la balise xml w:tr, chaque colonne par w:tc.
A partir du moment ou l'on peut se positionner sur un emplacement du tableau en recherchant un élément de texte il devient facile de repérer la racine du tableau:
Il suffit de trouver le début de la ligne, et le parent immédiat d'une ligne, c'est la racine du tableau.
//------------------------------------------------------------
TiXmlNode* ParseXMLDocument::GetGridRowNode(TiXmlNode* pNode) // recherche de la ligne d'apres l'emplacement pNode
{
if(!CompareValue(pNode,_T("w:tr")))
do
{
pNode=pNode->Parent();
}
while(!CompareValue(pNode,_T("w:tr")));
return pNode;
}
<code langage="cpp"><![CDATA[
//------------------------------------------------------------
TiXmlNode* ParseXMLDocument::GetGrid(TiXmlNode* pNode)
{
if(CompareValue(pNode,_T("w:tbl"))) return pNode;
TiXmlNode* pGrid=GetGridRowNode(pNode);
return pGrid->Parent();
}
Note :
Le fichier étant au format UTF-8 les méthodes Replace et Find gèrent l'encodage et le décodage des chaines manipulées.
Descriptions des méthodes :
ParseXMLDocument(const TCHAR *szdocumentFile=NULL);Constructeur par défaut, si szdocumentFile est non nulle Parse est appelée.
void SetDocumentFile(const TCHAR *szdocumentFile);Fixe le nom du document à analyser.
virtual bool Parse();Lance l'analyse
virtual TiXmlText* Find(const TCHAR *szText);Cherche un texte et renvoie un pointeur sur la branche texte le contenant.
virtual bool Replace(const TCHAR *szTextSrc,const TCHAR *szTextDest);Remplace un text szTextSrc par szTextDest dans tout le fichier XML.
virtual int Replace(const std::vector<CString> &arTextSrc,const std::vector<CString> &arTextDest);Remplace une liste de zone arTextSrc par des éléments contenus dans arTextDest
TiXmlNode* GetGrid(const TCHAR *szText);Retrouve la racine du grid d'après le texte d'une des cellules de ce grid. Renvoie null si la recherche échoue
TiXmlNode* GetGrid(TiXmlNode* pNode);Retrouve la racine du grid d'après l'emplacement en cours. Renvoie null si la recherche échoue
TiXmlNode* GetGridRowNode(TiXmlNode* pNode);Retrouve la ligne courante à partir de l'emplacement en cours, (remonte dans l'arborescence) Renvoie null si la recherche échoue
TiXmlNode* GetGridRowNode(TiXmlNode* pGrid,int nRow);Retourne la ligne nRow pour pGrid, pGrid doit être le sommet du tableau (w:tbl) Renvoie null si la recherche échoue
void DuplicateGridRow(TiXmlNode* pGrid,int nRow,int nAddRow=1);Duplique une ligne à partir de la ligne nRow pour le grid désigné par pGrid.
bool SetGridTextCol(TiXmlNode* pRowGrid,int nCol,TCHAR *szText);Fixe le texte pour la ligne en cours pour la cellule nCol,l'indicage commence a 0.
bool GetGridTextCol(TiXmlNode* pRowGrid,int nCol,CString &rText);Renvoie le texte pour la ligne en cours pour la cellule nCol, l'indexage commence à 0.
int GetGridColSize(TiXmlNode* pGrid);Renvoie le nombre de ligne pour le grid désigné par pGrid
int GetGridRowSize(TiXmlNode* pGrid);Renvoie le nombre de colonne pour le grid désigné par pGrid
TiXmlNode *FindTextNode(TiXmlNode* pNode,TCHAR *szLabel);
Recherche la zone texte szLabel pour le nœud pNode et le label xml szLabel.
Renvoie null si la recherche échoue
bool CompareValue(TiXmlNode* pNode,TCHAR *szToValue);Renvoie true si pNode->Value()==szToValue
virtual bool WriteXML(const TCHAR *szdocumentFile=NULL,bool bOptimise=true);
Sauvegarde le fichier XML, si szdocumentFile est nulle prend le nom du document d'analyse.
si bOptimise==true enlève les blancs et les cr+lf pour gagner de la place.
Exemple d'utilisation :
UnzipFile Unzip;
Unzip.SetZipPath(_T("RELANCECLIENT.docx"));
CString str;
if(!Unzip.Unzip())
#ifdef _DEBUG
afxDump << _T("erreur") << Unzip.GetLastError() ;
#else
{
str=_T("erreur ")+Unzip.GetLastError();
AfxMessageBox(str);
}
#endif
else
{
ParseXMLDocument Parse(Unzip.GetUnZipFolder()+_T("\\word\\document.xml"));
// cherche le tableau ayant une cellule nommée GRID
TiXmlNode* pGrid=Parse.GetGrid(_T("<GRID>"));
int nRow=Parse.GetGridRowSize(pGrid);
int nCol=Parse.GetGridColSize(pGrid);
// insere 2 lignes a partir de la ligne 1 du tableau.
Parse.DuplicateGridRow(pGrid,1,2);
// récupère la ligne 1 du grid.
TiXmlNode* pRow=Parse.GetGridRowNode(pGrid,1);
// affecte les colonnes de la ligne pRow.
Parse.SetGridTextCol(pRow,0,_T("01/08/2008"));
Parse.SetGridTextCol(pRow,1,_T("31/08/2008"));
Parse.SetGridTextCol(pRow,2,_T("Libellé"));
Parse.SetGridTextCol(pRow,3,_T("2008150"));
Parse.SetGridTextCol(pRow,4,_T("libellé essai"));
Parse.SetGridTextCol(pRow,5,_T("100.00"));
Parse.SetGridTextCol(pRow,6,_T("200.00"));
// écriture finale du document.
Parse.WriteXML(_T("document.xml"),false);
}La classe WordXML:
Son role :
C'est la classe d'interface pour gérer le mailing. Pour cela elle utilise les classes précédemment décrites, les composants de compression, décompression, d'analyse XML , ces objets devenant transparents à l'utilisation.
Elle permet entre autres quelques traitements sur le document final :
sa visualisation dans Word, son impression sur une imprimante spécifiée, et enfin la génération au format PDF en utilisant l'imprimante PDF que j'ai décrit dans un autre article
Descriptions des méthodes :
WordXML();Constructeur par défaut, initialise par défaut les différents composants pour la compression/décompression et l'analyse XML. comme le montre le code ci-dessous.
WordXML::WordXML():m_pUnzipObj(NULL),m_pZipObj(NULL),m_pParserObj(NULL),m_pCurrentGrid(NULL),m_pCurrentGridRow(NULL),m_nCurrentRow(0)
{
try
{
m_pUnzipObj=new UnzipFile;
m_pZipObj= new ZipDocx;
m_pParserObj= new ParseXMLDocument;
m_strDefaultPrinter=m_strDefaultPrinterOrg=GetDefPrinter();
}
catch(...)
{
delete m_pUnzipObj;
delete m_pZipObj;
delete m_pParserObj;
throw;
}
}bool SetUnzipObj(UnzipFile *pUnzipObj);Fixe l'objet de décompression, détruit l'objet précédent.
UnzipFile *GetUnzipObj()Renvoie l'objet courant de décompression.
bool SetZipFilesObj(ZipFiles *pZipObj);Fixe l'objet de compression, détruit l'objet précédent.
ZipFiles *GetZipFilesObj()Renvoie l'objet courant de compression
bool SetParserObj(ParseXMLDocument *pParserObj)Fixe l'objet d'analyse XML, détruit l'objet précédent.
ParseXMLDocument *GetParserObj()renvoie l'objet courant d'analyse XML.
bool SetModelDocument(const TCHAR *szDocument);Fixe le nom du document modèle.
CString GetModelDocument()Renvoie le nom du document modèle.
void SetDestinationFolder(const TCHAR *szFolder)Fixe le répertoire de destination pour le stockage du document généré.
bool CloseModel()Fermeture du modèle en cours.
void SetDocument(const TCHAR *szDocument)Fixe le nom du document à générer
CString GetDocument()Renvoie le nom du document à générer.
bool ViewDocument(const TCHAR *szDocument=NULL)
Lance la visualisation du document szDocument ou du document spécifié par SetDocument.
L'application Windows par défaut est appelée.
bool PrintDocument(const TCHAR *szPrinterName=NULL,const TCHAR *szDocument=NULL)
Lance l'impression du document szDocument sur l'imprimante szPrinterName,
si szPrinterName est nulle utilise l'imprimante par défaut windows,
si szDocument est nulle utilise le nom du document spécifié par SetDocument.
bool SetDefPrinter(const TCHAR *szPrinterName)Fixe l'imprimante par défaut Windows, l'ancienne imprimante par défaut est mémorisée.
CString GetDefPrinter()Renvoie le nom de l'imprimante par défaut Windows.
bool RestoreDefPrinter()Restitue l'imprimante par défaut Windows initiale.
bool FindText(const TCHAR *szText)Cherche une zone de texte dans le document.
bool ReplaceText(const TCHAR *szTextSrc,const TCHAR *szTextDest)Remplace une zone szTextSrc par un autre szTextDest
int ReplaceText(const std::vector<CString> &arTextSrc,const std::vector<CString> &arTextDest)
Remplace une liste de zone texte arTextSrc par les éléments contenus dans arTextDest
Renvoie le nombre d'occurrences trouvées.
bool GetGrid(const TCHAR *szText);Retrouve et mémorise la racine du grid d'après le texte d'une des cellules de ce grid.
bool GetGridRow(int nRow);Fixe la ligne de travail à nRow pour le grid en cours (GetGrid)
bool DuplicateGridRow(int nRow,int nAddRow=1);Duplique une ligne à partir de la ligne en cours (GetGridRow) nRow pour le grid en cours (GetGrid)
bool SetGridTextCol(int nCol,TCHAR *szText);Fixe le texte pour la ligne en cours pour la cellule nCol, l'indexage commence à 0.
bool GetGridTextCol(int nCol,CString &rText);Renvoie le texte pour la ligne en cours pour la cellule nCol, l'indexage commence à 0.
int GetGridColSize();Renvoie le nombre de lignes pour le grid en cours (GetGrid)
int GetGridRowSize();Renvoie le nombre de colonnes pour le grid en cours (GetGrid)
bool SaveDocument(const TCHAR *szDocumentName)Sauvegarde le document avec le nom spécifié par szDocumentName
CStringA GetLastError()Renvoie la dernière erreur détectée.
void SetPdfAppRun(bool bEnable=false)Active/désactive le lancement du programme à la fin du document.
void SetPdfFileName(const TCHAR *szFilename)Fixe le nom pour la génération du fichier.
CString GetLastPdfFileName()
Renvoie le dernier nom fixé par SetPdfFileName
Utilisation :
WordXML WXml;
if(!WXml.SetModelDocument(_T("RELANCECLIENT.docx")))
{
#ifdef _DEBUG
afxDump << _T("erreur") << WXml.GetLastError() ;
#else
{
CString str;
str=_T("erreur ")+WXml.GetLastError();
AfxMessageBox(str);
}
#endif
}
else
{
std::vector<CString> strKeyWord;
std::vector<CString> strValue;
strKeyWord.push_back(_T("<NOM>")); strValue.push_back(_T("Dawkins"));
strKeyWord.push_back(_T("<PRENOM>")); strValue.push_back(_T("Richard"));
strKeyWord.push_back(_T("<ADRESSE1>")); strValue.push_back(_T("P.O. Box 13604"));
strKeyWord.push_back(_T("<ADRESSE2>")); strValue.push_back(_T("Savannah,"));
strKeyWord.push_back(_T("<CP>")); strValue.push_back(_T("GA 31416"));
strKeyWord.push_back(_T("<VILLE>")); strValue.push_back(_T("USA"));
strKeyWord.push_back(_T("<COMPTE>")); strValue.push_back(_T("0000001"));
strKeyWord.push_back(_T("<DEBIT>")); strValue.push_back(_T("200.00"));
strKeyWord.push_back(_T("<CREDIT>")); strValue.push_back(_T("50.00"));
strKeyWord.push_back(_T("<SOLDEB>")); strValue.push_back(_T("150.00"));
strKeyWord.push_back(_T("<SOLCRE>")); strValue.push_back(_T(""));
strKeyWord.push_back(_T("<SOLDE>")); strValue.push_back(_T("150.00"));
WXml.ReplaceText(strKeyWord,strValue);
if(WXml.GetGrid(_T("<GRID>")))
{
WXml.DuplicateGridRow(1);
int nRow=WXml.GetGridRowSize();
int nCol=WXml.GetGridColSize();
WXml.GetGridRow(1);
WXml.SetGridTextCol(0,_T("01/08/08"));
WXml.SetGridTextCol(1,_T("31/08/2008"));
WXml.SetGridTextCol(2,_T("Libellé"));
WXml.SetGridTextCol(3,_T("2008150"));
WXml.SetGridTextCol(4,_T("libellé essai"));
WXml.SetGridTextCol(5,_T("100.00"));
WXml.SetGridTextCol(6,_T("24.00"));
WXml.GetGridRow(2);
WXml.SetGridTextCol(0,_T("15/08/08"));
WXml.SetGridTextCol(1,_T("15/09/2008"));
WXml.SetGridTextCol(2,_T("Libellé 2"));
WXml.SetGridTextCol(3,_T("2008151"));
WXml.SetGridTextCol(4,_T("libellé essai2"));
WXml.SetGridTextCol(5,_T("100.00"));
WXml.SetGridTextCol(6,_T("26.00"));
}
WXml.SaveDocument(_T("cour0001.docx"));
WXml.ViewDocument();
// deuxieme document.
strValue.erase(strValue.begin());
strValue.insert(strValue.begin(),_T("farscape"));
WXml.ReplaceText(strKeyWord,strValue);
if(WXml.GetGrid(_T("<GRID>")))
{
WXml.DuplicateGridRow(1);
int nRow=WXml.GetGridRowSize();
int nCol=WXml.GetGridColSize();
WXml.GetGridRow(1);
WXml.SetGridTextCol(0,_T("01/08/08"));
WXml.SetGridTextCol(1,_T("31/08/2008"));
WXml.SetGridTextCol(2,_T("Libellé"));
WXml.SetGridTextCol(3,_T("2008150"));
WXml.SetGridTextCol(4,_T("libellé essai"));
WXml.SetGridTextCol(5,_T("100.00"));
WXml.SetGridTextCol(6,_T("24.00"));
WXml.GetGridRow(2);
WXml.SetGridTextCol(0,_T("15/08/08"));
WXml.SetGridTextCol(1,_T("15/09/2008"));
WXml.SetGridTextCol(2,_T("Libellé 2"));
WXml.SetGridTextCol(3,_T("2008151"));
WXml.SetGridTextCol(4,_T("libellé essai2"));
WXml.SetGridTextCol(5,_T("100.00"));
WXml.SetGridTextCol(6,_T("26.00"));
}
WXml.SaveDocument(_T("cour0002.docx"));
WXml.ViewDocument();
WXml.CloseModel();
}
Le code ci-dessus génère deux documents à partir du modèle relanceclient.docx.
Ces classes sont utilisables dans les configurations suivantes:
Avec Visual 6.0 :
- En Unicode et multi-bytes
- Avec ou sans MFC : une classe de substitution est implémentée pour la classe CString avec les versions CStringA et CStringW suivant le contexte.
Avec Visual 2008 :
- En Unicode et multi-bytes
- Avec ou sans MFC, dans la configuration sans MFC : une classe de substitution est implémentée pour la classe CString, CStringA et CStringW.
V. L'interface C▲
Voici la liste des fonctions disponibles :
WXML_EXPORT int WXmlSetModelDocument(const XML_CHAR *szDocument);
WXML_EXPORT const XML_CHAR *WXmlGetModelDocument();
WXML_EXPORT void WXmlSetDestinationFolder(const XML_CHAR *szFolder);
WXML_EXPORT void WXmlSetDocument(const XML_CHAR* szDocument);
WXML_EXPORT const XML_CHAR *WXmlGetDocument();
WXML_EXPORT void WXmlListClearReplace();
WXML_EXPORT void WXmlListAddReplace(const XML_CHAR *szKeyWord,const XML_CHAR *szValue);
WXML_EXPORT int WXmlListReplace();
WXML_EXPORT int WXmlReplaceText(const XML_CHAR *szKeyWord,const XML_CHAR *szValue);
WXML_EXPORT int WXmlFindText(const XML_CHAR *szText);
WXML_EXPORT int WXmlGetGrid(const XML_CHAR *szText);
WXML_EXPORT int WXmlGetGridRow(int nRow);
WXML_EXPORT int WXmlDuplicateGridRow(int nRow,int nAddRow);
WXML_EXPORT int WXmlSetGridTextCol(int nCol,XML_CHAR *szText);
WXML_EXPORT int WXmlGetGridTextCol(int nCol,XML_CHAR *szText,int nBufSizeMax);
WXML_EXPORT int WXmlGetGridColSize();
WXML_EXPORT int WXmlGetGridRowSize();
WXML_EXPORT int WXmlSaveDocument(const XML_CHAR *szFileName);
WXML_EXPORT int WXmlPrintDocument(const XML_CHAR *szPrinterName);
WXML_EXPORT int WXmlViewDocument(const XML_CHAR *szDocument);
WXML_EXPORT int WXmlCloseModel();
WXML_EXPORT int WXmlSetDefaultPrinter(const XML_CHAR *szPrinterName);
WXML_EXPORT const XML_CHAR *WXmlGetDefaultPrinter();
WXML_EXPORT int WXmlRestoreDefaultPrinter();
WXML_EXPORT const char* WXmlGetLastError();
WXML_EXPORT int WXmlEmptyDirectory(const XML_CHAR *szDir,int bRemoveDir);
WXML_EXPORT int WXmlGetSizeJobForPrinter(const XML_CHAR *szPrinterName);
WXML_EXPORT void WXmlSetPdfFileName(const XML_CHAR *szFilename);
WXML_EXPORT const XML_CHAR* WXmlGetLastPdfFileName();
WXML_EXPORT void WXmlSetPdfAppRun(int bEnable);Utilisation dans un programme console en C :
void test()
{
struct ZONEWORD
{
const TCHAR *szLabel;
TCHAR *pszItem;
};
struct ZONEWORD zoneWord[]=
{
_T("<PREFIXE>") ,_T("Monsieur "),
_T("<NOM>") ,_T("Dawkins"),
_T("<PRENOM>") ,_T("Richard "),
_T("<ADRESSE1>") ,_T("P.O. Box 13604"),
_T("<ADRESSE2>") ,_T("Savannah,"),
_T("<CP>") ,_T("GA 31416"),
_T("<VILLE>") ,_T("USA"),
_T("<COMPTE>") ,_T("0000001"),
_T("<DEBIT>") ,_T("200.00"),
_T("<CREDIT>") ,_T("50.00"),
_T("<SOLDEB>") ,_T("150.00"),
_T("<SOLCRE>") ,_T(""),
_T("<SOLDE>") ,_T("150.00"),
};
int i,nRow,nCol;
// fixe le nom du modèle
WXmlSetModelDocument(_T("RELANCECLIENT.docx"));
// Le nom du document à générer
WXmlSetDocument(_T("cour0001.docx"));
// vide la liste interne de remplacement de zones.
WXmlListClearReplace();
// prepare la liste des remplacements a effectuer.
for(i=0;i<sizeof(zoneWord)/sizeof(struct ZONEWORD);i++)
{
WXmlListAddReplace(zoneWord[i].szLabel,zoneWord[i].pszItem);
}
// affecte le grid.
if(WXmlGetGrid(_T("<GRID>")))
{
WXmlDuplicateGridRow(1,1);
nRow=WXmlGetGridRowSize();
nCol=WXmlGetGridColSize();
WXmlGetGridRow(1);
WXmlSetGridTextCol(0,_T("01/08/08"));
WXmlSetGridTextCol(1,_T("31/08/2008"));
WXmlSetGridTextCol(2,_T("Libellé"));
WXmlSetGridTextCol(3,_T("2008150"));
WXmlSetGridTextCol(4,_T("libellé essai"));
WXmlSetGridTextCol(5,_T("100.00"));
WXmlSetGridTextCol(6,_T("24.00"));
WXmlGetGridRow(2);
WXmlSetGridTextCol(0,_T("15/08/08"));
WXmlSetGridTextCol(1,_T("15/09/2008"));
WXmlSetGridTextCol(2,_T("Libellé 2"));
WXmlSetGridTextCol(3,_T("2008151"));
WXmlSetGridTextCol(4,_T("libellé essai2"));
WXmlSetGridTextCol(5,_T("100.00"));
WXmlSetGridTextCol(6,_T("26.00"));
}
// désactive le lancement de l'application pdf associée.
WXmlSetPdfAppRun(0);
// remplace les zones
WXmlListReplace();
// sauvegarde le document
WXmlSaveDocument(NULL);
// fixe le nom du document pdf à générer
WXmlSetPdfFileName(_T("letter0001"));
// imprime sur l'imprimante pdf.
WXmlPrintDocument(_T("GhostScript PDF Writer"));
// le nouveau nom du document à générer
WXmlSetDocument(_T("cour0002.docx"));
WXmlListClearReplace();
for(i=0;i<sizeof(zoneWord)/sizeof(struct ZONEWORD);i++)
{
WXmlListAddReplace(zoneWord[i].szLabel,zoneWord[i].pszItem);
}
WXmlListReplace();
if(WXmlGetGrid(_T("<GRID>")))
{
WXmlDuplicateGridRow(1,1);
nRow=WXmlGetGridRowSize();
nCol=WXmlGetGridColSize();
WXmlGetGridRow(1);
WXmlSetGridTextCol(0,_T("01/08/08"));
WXmlSetGridTextCol(1,_T("31/08/2008"));
WXmlSetGridTextCol(2,_T("Libellé"));
WXmlSetGridTextCol(3,_T("2008150"));
WXmlSetGridTextCol(4,_T("libellé essai"));
WXmlSetGridTextCol(5,_T("100.00"));
WXmlSetGridTextCol(6,_T("24.00"));
WXmlGetGridRow(2);
WXmlSetGridTextCol(0,_T("15/08/08"));
WXmlSetGridTextCol(1,_T("15/09/2008"));
WXmlSetGridTextCol(2,_T("Libellé 2"));
WXmlSetGridTextCol(3,_T("2008151"));
WXmlSetGridTextCol(4,_T("libellé essai2"));
WXmlSetGridTextCol(5,_T("100.00"));
WXmlSetGridTextCol(6,_T("26.00"));
}
// fixe le nouveau nom du document pdf à générer
WXmlSetPdfFileName(_T("letter0002"));
WXmlSaveDocument(NULL);
WXmlPrintDocument(_T("GhostScript PDF Writer"));
// attente de la fin d'impression
while(WXmlGetSizeJobForPrinter(_T("GhostScript PDF Writer")));
// active le lancement de l'application par defaut associée à l'imprimante pdf.
WXmlSetPdfAppRun(1);
}
L'exemple ci-dessus est issu du programme de test TestDLLC disponible dans le projet sous Visual 2008.
Il illustre la génération avec les commandes C de deux documents docx à partir d'un modèle existant.
Une fois générés les documents sont transformés en fichier PDF grâce à l'imprimante PDF que j'ai développée dans un autre tutoriel (voir plus bas pour les liens).
L'exemple fonctionne en mode multi-bytes et Unicode.
la DLL produite n'utilise pas les classes CString, CStringW, CStringA des MFC, mais une classe patron de substitution que j'ai implémentée d'après la classe string de tinyXML.
Cette classe pourra être utilisée avec le compilateur VC 6.0 pour disposer de CStringA et CStringW.
Définition de la classe:
#ifdef WXML_VC6_STRING
#define WXML_MFC_STRING
#endif
#ifdef WXML_MFC_STRING
#pragma once
#include <assert.h>
#include <string.h>
#include <wchar.h>
#include <mbstring.h>
#include <stdio.h>
#include <stdarg.h>
/*
CStringT est une emulation de la classe CStringT MFC, seules les fonctions courantes sont implémentées,
on disposera des classes CString,CStringW,CStringA
*/
template<typename TYPE>
class CStringT
{
public :
// The size type used
typedef size_t size_type;
// Error value for find primitive
const size_type npos; // = -1;
// CStringT empty constructor
CStringT () : npos(static_cast<size_type >(-1))
{
nullrep_.size=0;
nullrep_.capacity=0;
nullrep_.str[0]='\0';
rep_=&nullrep_;
}
// CStringT copy constructor
CStringT ( const CStringT & copy) : rep_(0),npos(static_cast<size_type >(-1))
{
nullrep_.size=0;
nullrep_.capacity=0;
nullrep_.str[0]='\0';
init(copy.length());
StringMemcpy(start(),copy.data(), length());
}
// CStringT constructor, based on a string
CStringT ( const char * copy) : rep_(0),npos(static_cast<size_type >(-1))
{
nullrep_.size=0;
nullrep_.capacity=0;
nullrep_.str[0]='\0';
int nlen=strlen(copy);
init( static_cast<size_type>( nlen ));
if(sizeof(TYPE)==sizeof(char)) memcpy(reinterpret_cast<void *>(start()),static_cast<const char*>(copy), length());
else
{
wchar_t *wsz= new wchar_t[nlen+1];
MultiByteToWideChar( CP_ACP, 0, copy,nlen,wsz,nlen);
wmemcpy(reinterpret_cast<wchar_t *>(start()),reinterpret_cast<const wchar_t*>(wsz), length());
delete [] wsz;
}
}
// CStringT constructor, based on a string
CStringT ( const wchar_t * copy) : rep_(0),npos(static_cast<size_type >(-1))
{
nullrep_.size=0;
nullrep_.capacity=0;
nullrep_.str[0]='\0';
int nlen=wcslen(copy);
init( static_cast<size_type>( nlen ));
if(sizeof(TYPE)!=sizeof(char)) wmemcpy(reinterpret_cast<wchar_t *>(start()),copy, length());
else
{
char *sz= new char[nlen+1];
WideCharToMultiByte( CP_ACP, 0, copy, -1, sz, nlen+1, NULL, NULL );
memcpy(reinterpret_cast<void *>(start()),sz, length());
delete []sz;
}
}
// CStringT constructor, based on a string
explicit CStringT ( const TYPE * str, size_type len) : rep_(0),npos(static_cast<size_type >(-1))
{
nullrep_.size=0;
nullrep_.capacity=0;
nullrep_.str[0]='\0';
init(len);
StringMemcpy(start(),str, len);
}
// CStringT destructor
~CStringT ()
{
quit();
}
// = operator
CStringT& operator = (const wchar_t * copy)
{
return assign(copy, (size_type)StringLen(copy));
}
// = operator
CStringT& operator = (const char * copy)
{
return assign(copy, (size_type)StringLen(copy));
}
// = operator
CStringT& operator = (const CStringT & copy)
{
return assign(copy.start(), copy.length());
}
//Extracts a substring of length nCount characters from this CStringT object, starting at position iFirst (zero-based).
CStringT Mid( size_type iFirst, int nCount) const
{
CStringT <TYPE>tmp;
if(iFirst >=size()) return tmp;
if(iFirst+nCount >=size()) nCount-=((iFirst+nCount)-size());
tmp.init(nCount);
memmove(tmp.start(), start()+iFirst, nCount*sizeof(TYPE));
return tmp;
}
//Extracts a substring from this CStringT object, starting at position iFirst (zero-based).
CStringT Mid( size_type iFirst ) const
{
CStringT <TYPE>tmp;
if(iFirst >=size()) return tmp;
int nCount=size()-iFirst;
tmp.init(nCount);
memmove(tmp.start(), start()+iFirst, nCount*sizeof(TYPE));
return tmp;
}
//Extracts the leftmost nCount characters from this CStringT object and returns a copy of the extracted substring.
CStringT Left( size_type nCount ) const
{
CStringT <TYPE>tmp;
if(nCount >=size()) nCount=size();
tmp.init(nCount);
memmove(tmp.start(), start(), nCount*sizeof(TYPE));
return tmp;
}
//Extracts the last (that is, rightmost) nCount characters from this CStringT object and returns a copy of the extracted substring.
CStringT Right( size_type nCount ) const
{
CStringT <TYPE>tmp;
if(nCount >=size()) nCount=size();
tmp.init(nCount);
int nOfs=size()-nCount;
memmove(tmp.start(), start()+nOfs, nCount*sizeof(TYPE));
return tmp;
}
// += operator. Maps to append
CStringT& operator += (const wchar_t * suffix)
{
return append(suffix, static_cast<size_type>( StringLen(suffix) ));
}
// += operator. Maps to append
CStringT& operator += (const char * suffix)
{
return append(suffix, static_cast<size_type>( StringLen(suffix) ));
}
// += operator. Maps to append
CStringT& operator += (TYPE single)
{
return append(&single, 1);
}
// += operator. Maps to append
CStringT& operator += (const CStringT & suffix)
{
return append(suffix.data(), suffix.length());
}
// Convert a CStringT into a null-terminated char *
operator const TYPE*() const{ return rep_->str; }
// Convert a CStringT into a null-terminated char *
const TYPE * c_str () const { return rep_->str; }
// Convert a CStringT into a char * (need not be null terminated).
const TYPE * data () const { return rep_->str; }
// Return the length of a CStringT
size_type length () const { return rep_->size; }
// Return the length of a CStringT, Alias for length()
int GetLength() const { return rep_->size; }
bool IsEmpty() const {return !size();}
// Alias for length()
size_type size () const { return rep_->size; }
// Checks if a CStringT is empty
bool empty () const { return rep_->size == 0; }
// Return capacity of string
size_type capacity () const { return rep_->capacity; }
// single char extraction
const TYPE at (size_type index) const
{
assert( index < length() );
return rep_->str[ index ];
}
// [] operator
TYPE operator [] (int index) const
{
assert(static_cast<unsigned int>( index) < length() );
return rep_->str[ index ];
}
// find a char in a string from an offset. Return CStringT::npos if not found
size_type Find (TYPE tofind, size_type offset=0) const
{
if (offset >= length()) return npos;
for (const TYPE * p = c_str() + offset; *p != '\0'; ++p)
{
if (*p == tofind) return static_cast< size_type >( p - c_str() );
}
return npos;
}
// find a string in a string from an offset. Return CStringT::npos if not found
size_type Find (const TYPE* pszSub, size_type offset=0)
{
if (offset >= length() || pszSub == NULL) return npos;
// find first matching substring
const TYPE *psz = StringFindString( c_str()+offset, pszSub );
// return -1 for not found, distance from beginning otherwise
return( (psz == NULL) ? npos : int( psz-c_str() ) );
}
// release buffer, setting length to nNewLength (or to first nul if -1)
void ReleaseBuffer(int nNewLength=-1)
{
if (nNewLength == -1) nNewLength = StringLen(c_str());
assert(static_cast<unsigned int>(nNewLength) <= size());
CStringT <TYPE>tmp;
tmp.init(nNewLength);
memmove(tmp.start(),start(),nNewLength*sizeof(TYPE));
swap(tmp);
}
TYPE* GetBuffer(int nMinBufLength)
{
assert(nMinBufLength >= 0);
int nOldLen = size();
if (nMinBufLength < nOldLen) nMinBufLength = nOldLen;
CStringT <TYPE>tmp;
tmp.init(nMinBufLength);
memcpy(tmp.start(), start(), (nOldLen+1)*sizeof(TYPE));
swap(tmp);
set_size(nOldLen);
return start();
}
// get pointer to modifiable buffer exactly as long as nNewLength
TYPE *GetBufferSetLength(int nNewLength)
{
assert(static_cast<unsigned int>(nNewLength) >= 0);
CStringT <TYPE>tmp;
tmp.init(nNewLength);
unsigned int nSize=nNewLength;
if(nSize>size()) nSize=size()+1;
memmove(tmp.start(),start(),nSize*sizeof(TYPE));
swap(tmp);
return const_cast<TYPE *>(c_str());
}
// Replace all occurrences of string 'pszOld' with string 'pszNew'
int Replace( const TYPE *pszOld,const TYPE* pszNew )
{
// can't have empty or NULL lpszOld
// nSourceLen is in TYPE
int nSourceLen = StringLen( pszOld );
if( nSourceLen == 0 ) return( 0 );
// nReplacementLen is in TYPE
int nReplacementLen = StringLen( pszNew );
// loop once to figure out the size of the result string
int nCount = 0;
{
TYPE * pszStart =const_cast<TYPE*>(c_str());
TYPE * pszEnd = pszStart+size();
while( pszStart < pszEnd )
{
TYPE* pszTarget;
while( (pszTarget =const_cast<TYPE*>( StringFindString( pszStart, pszOld ) )) != NULL)
{
nCount++;
pszStart = pszTarget+nSourceLen;
}
pszStart += StringLen( pszStart )+1;
}
}
// if any changes were made, make them
if( nCount > 0 )
{
// if the buffer is too small, just
// allocate a new buffer (slow but sure)
int nOldLength = size();
int nNewLength = nOldLength+(nReplacementLen-nSourceLen)*nCount;
CStringT <TYPE>tmp;
tmp.init(__max( nNewLength, nOldLength ) );
memmove(tmp.start(),start(),size()*sizeof(TYPE));
TYPE * pszBuffer =const_cast<TYPE*>( tmp.c_str());
TYPE * pszStart = pszBuffer;
TYPE * pszEnd = pszStart+nOldLength;
// loop again to actually do the work
while( pszStart < pszEnd )
{
TYPE * pszTarget;
while( (pszTarget = const_cast<TYPE*>(StringFindString( pszStart, pszOld ) )) != NULL )
{
int nBalance = nOldLength-int(pszTarget-pszBuffer+nSourceLen);
memmove( pszTarget+nReplacementLen,pszTarget+nSourceLen, nBalance*sizeof( TYPE ) );
memcpy( pszTarget,pszNew, nReplacementLen*sizeof( TYPE ) );
pszStart = pszTarget+nReplacementLen;
pszTarget[nReplacementLen+nBalance] = 0;
nOldLength += (nReplacementLen-nSourceLen);
}
pszStart += StringLen( pszStart )+1;
}
assert( pszBuffer[nNewLength] == 0 );
swap(tmp);
}
return( nCount );
}
// Converts all the characters in this string to uppercase characters.
CStringT& MakeUpper()
{
StringMemcpy(start(),Strupper(const_cast<TYPE *>(data())), length());
return *this;
}
//Trims trailing whitespace characters from the string.
void TrimRight()
{
TYPE * lpsz = start();
TYPE * lpszLast = NULL;
while (*lpsz != '\0')
{
if (isSpace(*lpsz))
{
if (lpszLast == NULL) lpszLast = lpsz;
}
else lpszLast = NULL;
lpsz++ ;
}
if (lpszLast != NULL)
{
*lpszLast = '\0';
rep_->size = (lpszLast - start())/sizeof(TYPE);
}
}
// Formats the string as sprintf does.
void Format(const char *szFormat,... )
{
assert(sizeof(TYPE)==sizeof(char));
va_list arg_ptr;
va_start(arg_ptr,szFormat);
CStringT <TYPE>tmp;
int nSize=_vscprintf(szFormat,arg_ptr);
tmp.init(nSize);
vsprintf(tmp.start(),szFormat,arg_ptr);
swap(tmp);
va_end(arg_ptr);
}
void Format(const wchar_t *szFormat,... )
{
assert(sizeof(TYPE)==sizeof(wchar_t));
va_list arg_ptr;
va_start(arg_ptr,szFormat);
CStringT <TYPE>tmp;
int nSize=_vscwprintf(szFormat,arg_ptr);
tmp.init(nSize);
vswprintf(tmp.start(),szFormat,arg_ptr);
va_end(arg_ptr);
swap(tmp);
}
// alias of clear
void Empty(){clear();}
void clear ()
{
//Lee:
//The original was just too strange, though correct:
// CStringT().swap(*this);
//Instead use the quit & re-init:
quit();
init(0,0);
}
/* Function to reserve a big amount of data when we know we'll need it. Be aware that this
function DOES NOT clear the content of the CStringT if any exists.
*/
void reserve (size_type cap)
{
if (cap > capacity())
{
CStringT<TYPE>tmp;
tmp.init(length(), cap);
StringMemcpy(tmp.start(),data(), length());
swap(tmp);
}
}
CStringT& assign (const wchar_t * str, size_type len)
{
void *pzon=reinterpret_cast<void *>(const_cast <wchar_t *>(str));
char *sz=NULL;
if(sizeof(TYPE)==sizeof(char))
{
sz= new char[len];
WideCharToMultiByte( CP_ACP, 0, str, -1, sz, len, NULL, NULL );
pzon=sz;
}
size_type cap = capacity();
if (len > cap || cap > 3*(len + 8))
{
CStringT <TYPE>tmp;
tmp.init(len);
memcpy(reinterpret_cast<void *>(tmp.start()),pzon,len*sizeof(TYPE));
swap(tmp);
}
else
{
memmove(start(), pzon, len*sizeof(TYPE));
set_size(len);
}
delete []sz;
return *this;
}
CStringT& assign (const char * str, size_type len)
{
void *pzon=reinterpret_cast<void *>(const_cast <char *>(str));
wchar_t *wsz=NULL;
if(sizeof(TYPE)==sizeof(wchar_t))
{
wsz= new wchar_t[len];
MultiByteToWideChar( CP_ACP, 0, str,len,wsz,len);
pzon=wsz;
}
size_type cap = capacity();
if (len > cap || cap > 3*(len + 8))
{
CStringT <TYPE>tmp;
tmp.init(len);
memcpy(reinterpret_cast<void *>(tmp.start()),pzon,len*sizeof(TYPE));
swap(tmp);
}
else
{
memmove(start(), pzon, len*sizeof(TYPE));
set_size(len);
}
delete []wsz;
return *this;
}
CStringT& append (const char* str, size_type len)
{
void *pzon=reinterpret_cast<void *>(const_cast <char *>(str));
wchar_t *wsz=NULL;
if(sizeof(TYPE)==sizeof(wchar_t))
{
wsz= new wchar_t[len];
MultiByteToWideChar( CP_ACP, 0, str,len,wsz,len);
pzon=wsz;
}
size_type newsize = length() + len;
if (newsize > capacity())
{
reserve (newsize + capacity());
}
memmove(finish(), pzon, len*sizeof(TYPE));
set_size(newsize);
delete []wsz;
return *this;
}
CStringT& append (const wchar_t* str, size_type len)
{
void *pzon=reinterpret_cast<void *>(const_cast <wchar_t *>(str));
char *sz=NULL;
if(sizeof(TYPE)==sizeof(char))
{
sz= new char[len];
WideCharToMultiByte( CP_ACP, 0, str, -1, sz, len, NULL, NULL );
pzon=sz;
}
size_type newsize = length() + len;
if (newsize > capacity())
{
reserve (newsize + capacity());
}
memmove(finish(), pzon, len*sizeof(TYPE));
set_size(newsize);
delete []sz;
return *this;
}
void swap (CStringT& other)
{
Rep* r = rep_;
// switch avec un chaine null.
bool bNull=(rep_ == &nullrep_);
rep_ = other.rep_;
// improbable ...
if(other.rep_==&other.nullrep_) rep_=&nullrep_;
other.rep_ = r;
if(bNull) other.rep_=&other.nullrep_;
}
static int Compare(const char *sz1,const char *sz2)
{
return strcmp(sz1,sz2);
}
static int Compare(const wchar_t *sz1,const wchar_t *sz2)
{
return wcscmp(sz1,sz2);
}
static int StringLen(const char *psz) {return strlen(psz);}
static int StringLen(const wchar_t *pwsz){return wcslen(pwsz);}
void init(size_type sz) { init(sz, sz); }
TYPE* start() const { return rep_->str; }
TYPE* finish() const { return rep_->str + rep_->size; }
private:
int isSpace(const char t){return isspace(t);}
int isSpace(const wchar_t t){return iswspace(t);}
char *Strupper(char *sz)
{
return _strupr(sz);
}
wchar_t *Strupper(wchar_t *sz)
{
return _wcsupr(sz);
}
const char *StringFindString( const char *pszBlock, const char *pszMatch )
{
return reinterpret_cast< const char* >( _mbsstr( reinterpret_cast< const unsigned char* >( pszBlock ),
reinterpret_cast< const unsigned char* >( pszMatch ) ) );
}
const wchar_t *StringFindString( const wchar_t *pszBlock, const wchar_t *pszMatch )
{
return reinterpret_cast< const wchar_t* >( wcsstr( pszBlock , pszMatch ) );
}
void StringMemcpy(char *dest,const char *src,size_t nlen)
{
memcpy(reinterpret_cast<void *>(dest),src,nlen);
}
void StringMemcpy(wchar_t *dest,const wchar_t *src,size_t nlen)
{
wmemcpy(dest,src,nlen);
}
void set_size(size_type sz) { rep_->str[ rep_->size = sz ] = '\0'; }
struct Rep
{
size_type size, capacity;
TYPE str[1];
};
void init(size_type sz, size_type cap)
{
if (cap)
{
// Lee: the original form:
// rep_ = static_cast<Rep*>(operator new(sizeof(Rep) + cap));
// doesn't work in some cases of new being overloaded. Switching
// to the normal allocation, although use an 'int' for systems
// that are overly picky about structure alignment.
const size_type bytesNeeded = sizeof(Rep) + (cap *sizeof(TYPE));
const size_type intsNeeded = ( bytesNeeded + sizeof(int) - 1 ) / sizeof( int );
rep_ = reinterpret_cast<Rep*>( new int[ intsNeeded ] );
rep_->str[ rep_->size = sz ] = '\0';
rep_->capacity = cap;
}
else
{
rep_ = &nullrep_;
}
}
void quit()
{
if (rep_ != &nullrep_)
{
// The rep_ is really an array of ints. (see the allocator, above).
// Cast it back before delete, so the compiler won't incorrectly call destructors.
delete [] ( reinterpret_cast<int*>( rep_ ) );
}
}
Rep * rep_;
Rep nullrep_;
} ;
template<typename TYPE>
inline bool operator == (const CStringT<TYPE> & a, const CStringT<TYPE> & b)
{
return CStringT<TYPE>::Compare(a.c_str(),b.c_str())==0;
}
template<typename TYPE>
inline bool operator == (const CStringT<TYPE> & a, const TYPE* b)
{
return CStringT<TYPE>::Compare(a.c_str(),b)==0;
}
template<typename TYPE>
inline bool operator == (const TYPE* a, const CStringT<TYPE> & b) { return b == a; }
template<typename TYPE>
inline bool operator < (const CStringT<TYPE> & a, const CStringT<TYPE> & b)
{
return CStringT<TYPE>::Compare(a.c_str(),b.c_str())<0;
}
template<typename TYPE>
inline bool operator < (const CStringT<TYPE> & a, const TYPE* b)
{
return CStringT<TYPE>::Compare(a.c_str(),b)<0;
}
template<typename TYPE>
inline bool operator < (const TYPE * a, const CStringT<TYPE> & b)
{
return CStringT<TYPE>::Compare(a,b.c_str())<0;
}
template<typename TYPE>
inline bool operator != (const CStringT<TYPE> & a, const CStringT<TYPE> & b) { return !(a == b); }
template<typename TYPE>
inline bool operator != (const CStringT<TYPE> & a, const TYPE* b) { return !(a == b); }
template<typename TYPE>
inline bool operator != (const TYPE* a, const CStringT<TYPE> & b) { return !(b == a); }
template<typename TYPE>
inline bool operator > (const CStringT<TYPE> & a, const CStringT<TYPE> & b) { return b < a; }
template<typename TYPE>
inline bool operator > (const TYPE* a, const CStringT<TYPE> & b) { return b < a; }
template<typename TYPE>
inline bool operator > (const CStringT<TYPE> & a, const TYPE* b) { return b < a; }
template<typename TYPE>
inline bool operator <= (const CStringT<TYPE> & a, const CStringT<TYPE> & b) { return !(b < a); }
template<typename TYPE>
inline bool operator <= (const TYPE* a, const CStringT<TYPE> & b) { return !(b < a); }
template<typename TYPE>
inline bool operator <= (const CStringT<TYPE> & a, const TYPE* b) { return !(b < a); }
template<typename TYPE>
inline bool operator >= (const CStringT<TYPE> & a, const CStringT<TYPE> & b) { return !(a < b); }
template<typename TYPE>
inline bool operator >= (const TYPE* a, const CStringT<TYPE> & b) { return !(a < b); }
template<typename TYPE>
inline bool operator >= (const CStringT<TYPE> & a, const TYPE* b) { return !(a < b); }
template<typename TYPE>
CStringT<TYPE>operator + (const CStringT<TYPE> & a, const CStringT<TYPE> & b)
{
CStringT<TYPE>tmp;
tmp.reserve(a.length() + b.length());
tmp += a;
tmp += b;
return tmp;
}
template<typename TYPE>
CStringT<TYPE> operator + (const CStringT<TYPE> & a, const TYPE* b)
{
CStringT <TYPE>tmp;
unsigned int b_len = CStringT<TYPE>::StringLen(b);
tmp.reserve(a.length() + b_len);
tmp += a;
tmp.append(b, b_len);
return tmp;
}
template<typename TYPE>
CStringT<TYPE> operator + (const TYPE* a, const CStringT<TYPE> & b)
{
CStringT <TYPE>tmp;
unsigned int a_len = CStringT<TYPE>::StringLen(a);
tmp.reserve(a_len + b.length());
tmp.append(a, a_len);
tmp += b;
return tmp;
}
#ifdef _UNICODE
#ifndef WXML_VC6_STRING // en mode MFC et visual 6.0 pas besoin de CString...
typedef CStringT<wchar_t> CString;
#endif
#else
#ifndef WXML_VC6_STRING // en mode MFC et visual 6.0 pas besoin de CString...
typedef CStringT<char> CString;
#endif
#endif
typedef CStringT<char> CStringA;
typedef CStringT<wchar_t> CStringW;
#endif // WXML_MFC_STRING
La directive WXML_VC6_STRING permet dans un projet MFC avec VC6.0 de disposer de CStringA et CStringW.
la directive WXML_MFC_STRING seule, permet de disposer des classes CString, CStringA et CStringW.
Cette DLL sera disponible dans les configurations suivantes:
Avec Visual 6.0 :
- En Unicode et multi-bytes
- Avec ou sans MFC : dépendra de la version de la DLL utilisée.
Avec Visual 2008 :
- En Unicode et multi-bytes
- Avec ou sans MFC : dépendra de la version de la DLL utilisée.
VI. Les différents modules de la solution▲
VI-a. L'interface pour OpenXml▲
Le projet TinyXML modifié en version visual6.0 et Visual 2008 :./tinyxml.zip
Le projet ZipArchive modifié en version visual6.0 et Visual 2008 :./ziparchive.zip
Le projet sous Visual 2008 contenant:./LibWordXML.zip
le projet contient les sous projets suivants:
- la DLL en C :LibWordXml
- le test de la DLL en C :TestDLLC :
- le test en MFC :TestLibWordXML, fonctionne dans les configurations: Release/debug/ReleaseUnicod/DebugUnicod
- le test en C++ mode console :TestClasse
La DLL pour l'interface C en version visual6.0 et Visual 2008 : il faudra ouvrir avec Visual 6 le projet LibWordXML.dsw contenu dans le répertoire principal
Le projet GhostPrinterPdf pour l'impression PDF :https://farscape.developpez.com/tutoriels/PrinterPDF/
Dans le projet Visual 2008 vous trouverez le modèle relanceClient.docx utilisé pour les tests.
VI-b. L'envoi des fichiers par Emails▲
Pour envoyer les fichiers par email j'ai utilisé une contribution disponible sur le site de CodeProjects : http://www.codeproject.com/KB/IP/csmtpconn.aspx
J'ai modifié le source qui date de 2000, pour qu'il soit compilable sous Visual 2008 dans un environnement Unicode ou Multi-Bytes.
Envoyer un mail est très simple et ce résume à ces quelques lignes :
//......
WXml.SaveDocument(_T("cour0001.docx"));
// send email.
{
CSMTPConnection smtp;
smtp.Connect(_T("smtp.neuf.fr"));
CSMTPMessage m;
m.AddRecipient(CSMTPAddress("yoyonovitch@neuf.fr"));
m.m_From = CSMTPAddress("edgard@neuf.fr");
m.m_sSubject = "votre lettre de relance";
CSMTPAttachment a;
a.Attach(WXml.GetDocument());
m.AddAttachment(&a);
smtp.SendMessage(m);
smtp.Disconnect();
}
WXml.ViewDocument();
J'ai mis en place l'envoi de l'email après la sauvegarde du document.
Vous trouverez ces lignes dans l'exemple TestLibWordXML, pensez à changer les adresses Emails …
VII. Conclusion▲
Cette implémentation est un premier pas, elle permet le remplacement de zones textes existantes dans un document Word,
et le remplissage d'un tableau, ce qui est amplement suffisant dans mon cas pour gérer un mailing simple.
Cette solution combinée à l'impression du document au format PDF permettra l'envoi de documents par mail dans un format connu de tous et protégé contre les modifications.
VIII. Remerciements▲
Je remercie toute l'équipe C++, pour leur relecture attentive du document, notamment PetitPapaNoël Merci à jbarreau-mainson pour la correction finale de cet article